In the chapter "massively scalable", the description of segregation example doesn't match the figure. This patch fix the description so that it matches the figure. Change-Id: Ib3429c2efcbfa1e1ecc994e8fb7f6dae9f241f1f Closes-Bug: #1484771
5.8 KiB
Technical considerations
Repurposing an existing OpenStack environment to be massively scalable is a formidable task. When building a massively scalable environment from the ground up, ensure you build the initial deployment with the same principles and choices that apply as the environment grows. For example, a good approach is to deploy the first site as a multi-site environment. This enables you to use the same deployment and segregation methods as the environment grows to separate locations across dedicated links or wide area networks. In a hyperscale cloud, scale trumps redundancy. Modify applications with this in mind, relying on the scale and homogeneity of the environment to provide reliability rather than redundant infrastructure provided by non-commodity hardware solutions.
Infrastructure segregation
OpenStack services support massive horizontal scale. Be aware that this is not the case for the entire supporting infrastructure. This is particularly a problem for the database management systems and message queues that OpenStack services use for data storage and remote procedure call communications.
Traditional clustering techniques typically provide high availability and some additional scale for these environments. In the quest for massive scale, however, you must take additional steps to relieve the performance pressure on these components in order to prevent them from negatively impacting the overall performance of the environment. Ensure that all the components are in balance so that if the massively scalable environment fails, all the components are near maximum capacity and a single component is not causing the failure.
Regions segregate completely independent installations linked only by an Identity and Dashboard (optional) installation. Services have separate API endpoints for each region, and include separate database and queue installations. This exposes some awareness of the environment's fault domains to users and gives them the ability to ensure some degree of application resiliency while also imposing the requirement to specify which region to apply their actions to.
Environments operating at massive scale typically need their regions or sites subdivided further without exposing the requirement to specify the failure domain to the user. This provides the ability to further divide the installation into failure domains while also providing a logical unit for maintenance and the addition of new hardware. At hyperscale, instead of adding single compute nodes, administrators can add entire racks or even groups of racks at a time with each new addition of nodes exposed via one of the segregation concepts mentioned herein.
Cells <cell>
provide the ability to subdivide the compute portion of an OpenStack
installation, including regions, while still exposing a single endpoint.
Each region has an API cell along with a number of compute cells where
the workloads actually run. Each cell has its own database and message
queue setup (ideally clustered), providing the ability to subdivide the
load on these subsystems, improving overall performance.
Each compute cell provides a complete compute installation, complete with full database and queue installations, scheduler, conductor, and multiple compute hosts. The cells scheduler handles placement of user requests from the single API endpoint to a specific cell from those available. The normal filter scheduler then handles placement within the cell.
Unfortunately, Compute is the only OpenStack service that provides good support for cells. In addition, cells do not adequately support some standard OpenStack functionality such as security groups and host aggregates. Due to their relative newness and specialized use, cells receive relatively little testing in the OpenStack gate. Despite these issues, cells play an important role in well known OpenStack installations operating at massive scale, such as those at CERN and Rackspace.
Host aggregates
Host aggregates enable partitioning of OpenStack Compute deployments into logical groups for load balancing and instance distribution. You can also use host aggregates to further partition an availability zone. Consider a cloud which might use host aggregates to partition an availability zone into groups of hosts that either share common resources, such as storage and network, or have a special property, such as trusted computing hardware. You cannot target host aggregates explicitly. Instead, select instance flavors that map to host aggregate metadata. These flavors target host aggregates implicitly.
Availability zones
Availability zones provide another mechanism for subdividing an installation or region. They are, in effect, host aggregates exposed for (optional) explicit targeting by users.
Unlike cells, availability zones do not have their own database server or queue broker but represent an arbitrary grouping of compute nodes. Typically, nodes are grouped into availability zones using a shared failure domain based on a physical characteristic such as a shared power source or physical network connections. Users can target exposed availability zones; however, this is not a requirement. An alternative approach is to set a default availability zone to schedule instances to a non-default availability zone of nova.
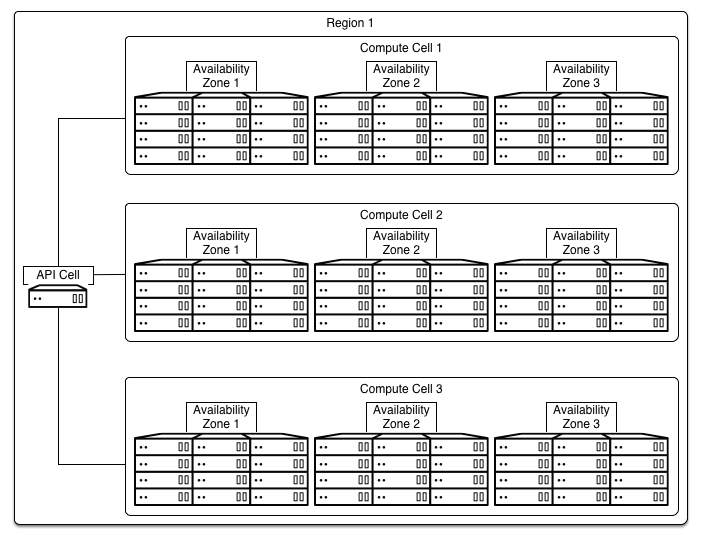
Segregation example
In this example, the cloud is divided into two regions, an API cell and three child cells for each region, with three availability zones in each cell based on the power layout of the data centers. The below figure describes the relationship between them within one region.
A number of host aggregates enable targeting of virtual machine instances using flavors, that require special capabilities shared by the target hosts such as SSDs, 10 GbE networks, or GPU cards.