As suggested open openstack-discuss ML[1], some sphinxcontrib packages have not been updated for several years and might going to be maintained anymore. In tacker-specs repo, many diagrams are compiled with sphinxcontrib-seqdiag and sphinxcontrib-nwdiag. This update is to drop using the packages and add image files instead. The embedded source codes are remained as separated files and named as "*.diag". In addition, it includes two updates other than that. * usage of the dropped diagram support described in the `specs/template.rst` is also removed because it's no longer supported. * Upgrade the version of `pillow` to the latest 11.0.0 since installation is failed if the version is old. [1] https://lists.openstack.org/archives/list/openstack-discuss@lists.openstack.org/message/4IID4UEXY4PJJGBTMFMTRYLKJIN4GOQ6/ Change-Id: I8cede6de0770b68a9984617643aa4aa81e47ba5c
24 KiB
Support Healing Kubernetes Master/Worker-nodes with Mgmtdriver
https://blueprints.launchpad.net/tacker/+spec/mgmt-driver-for-k8s-heal
This specification describes enhancement of Heal operation for the VNF which includes Kubernetes cluster.
Problem description
The ETSI-compliant VNF Heal operation has been implemented in
Ussuri release and updated to support Notification and
Grant operations in Victoria release. For the use case with
OS container based VNF with Kubernetes cluster, it's important to
support the cluster management. In this spec, we propose the Heal
operation for Kubernetes Master or Worker-nodes when the VNF is composed
of Kubernetes cluster with the spec mgmt-driver-for-k8s-cluster.
To support healing Kubernetes cluster nodes, MgmtDriver needs to be
extended. After deploying a Kubernetes cluster using MgmtDriver as the
VNF Lifecycle Management interface with ETSI NFV-SOL 0031,
the heal related operations are required. When healing a Master or
Worker-node, you need not only the default Heal operation, but also the
heal_end operation to register the node to an existing
Kubernetes cluster. If you want to heal a Master-node, you need to
configure etcd and HA proxy. Also, when healing a Worker-node, you need
to apply the required configuration and to make it to leave and join the
cluster with the same way in scale-in and scale-out.
Proposed change
The two patterns of Heal operations are supported:
- Heal a single node (Master / Worker) in Kubernetes cluster based on
ETSI NFV-SOL0022.
Heal Master-node of Kubernetes cluster
Delete a failed Master-node, create a new VM, and incorporate a new Master-node into the existing Kubernetes cluster. The etcd cluster and the load balancer configured as a Master-node are also repaired by MgmtDriver.
Heal Worker-node of Kubernetes cluster
Delete the failed Worker-node, create a new VM, and incorporate the new Worker-node into the existing Kubernetes cluster.
- Heal the entire Kubernetes cluster based on ETSI NFV-SOL0033.
Note
The Healing of the Pods in the Kubernetes cluster is out of scope of this specification.
Note
Failure detection is also out of scope. It is assumed that the user performs a Heal operation to the known node being failed.
Note
Kubernetes v1.16.0 and Kubernetes python client v11.0 are supported for Kubernetes VIM.
VNFD for Healing operation
VNFD needs to have heal_start and heal_end
definitions in interfaces as the following sample:
node_templates:
VNF:
...
interfaces:
Vnflcm:
...
heal_start:
implementation: mgmt-drivers-kubernetes
heal_end:
implementation: mgmt-drivers-kubernetes
artifacts:
mgmt-drivers-kubernetes:
description: Management driver for kubernetes cluster
type: tosca.artifacts.Implementation.Python
file: /.../mgmt_drivers/kubernetes_mgmt.py
MasterVDU:
type: tosca.nodes.nfv.Vdu.Compute
...
WorkerVDU:
type: tosca.nodes.nfv.Vdu.Compute
...Request data for Healing operation
User gives following heal parameter to "POST
/vnf_instances/{id}/heal" as HealVnfRequest data type. It
is not the same in SOL002 and SOL003.
In ETSI NFV-SOL002 v2.6.14:
Attribute name Parameter description vnfcInstanceId User specify heal target, user can know "vnfcInstanceId" by InstantiatedVnfInfo.vnfcResourceInfothat contained in the response of "GET /vnf_instances/{id}".cause Not needed additionalParams Not needed healScript Not needed
In ETSI NFV-SOL003 v2.6.15:
Attribute name Parameter description cause Not needed additionalParams Not needed
Tacker in Ussuri release, vnfcInstanceId,
cause, and additionalParams are supported for
both of SOL002 and SOL003.
If the vnfcInstanceId parameter is null, this means that healing operation is required for the entire Kubernetes cluster, which is the case in SOL003.
Following is a sample of healing request body for SOL002:
{
"vnfcInstanceId": "311485f3-45df-41fe-85d9-306154ff4c8d"
}Healing a node in Kubernetes cluster with SOL002
Healing a Master-node
The following changes are needed:
- Extend MgmtDriver to support
heal_startandheal_end- In
heal_start, the target node is removed from the Kubernetes cluster by deleting it from the etcd cluster and disabling the load balance in HA proxy. These are executed in a sample script invoked in MgmtDriver. - In
heal_end, MgmtDriver invokes a sample script to install and configure the new Master-node, to add it to the etcd cluster, and to register in HA proxy for load balancing.
- In
Note
It is assumed that the required information for Heal operation in MgmtDriver is stored in the additional parameter of the Instantiate and/or Heal request. MgmtDriver passes them to the sample script.
The diagram below shows the Heal VNF operation for a Master-node:
+---------------+
| Heal |
| Request with |
| Additional |
| Params |
+---+-----------+
|
+----------------+-----------+
| v VNFM |
| +-------------------+ |
| | Tacker-server | |
| +---------+---------+ |
| | |
4. heal_end | v |
Kubernetes cluster | +----------------------+ |
(Master) | | +-------------+ | |
+----------------------+--+----| MgmtDriver | | |
| | | +-----------+-+ | |
| | | | | |
| | | 1. heal_start | | |
| | | Kubernetes | | |
+--------------------+----------+ | | cluster | | |
| | | | | (Master)| | |
| | | | | | | |
| | | | | | | |
| +----------+ +---+------+ | | | | | |
| | | | v | | 3. Create | | +-----------+ | | |
| | +------+ | | +------+ | | new VM | | |OpenStack | | | |
| | |Worker| | | |Master| |<--------------+--+-|InfraDriver| | | |
| | +------+ | | +------+ | | | | +------+----+ | | |
| | VM | | VM | | | | | | | |
| +----------+ +----------+ | | | | | | |
| +----------+ +----------+ | 2. Delete | | | | | |
| | +------+ | | +------+ | | failed VM | | | | | |
| | |Worker| | | |Master| |<--+-----------+--+--------+ | | |
| | +------+ | | +------+ | | | | | | |
| | VM | | VM |<--+-----------+--+----------------+ | |
| +----------+ +----------+ | | | | |
+-------------------------------+ | | Tacker-conductor| |
+-------------------------------+ | +----------------------+ |
| Hardware Resources | | |
+-------------------------------+ +----------------------------+The diagram shows related component of this spec proposal and an overview of the following processing:
- MgmtDriver pre-processes to remove Master-node from the existing
etcd cluster in
heal_startbefore deleting the failed VM.- Remove the failed Master-node from etcd cluster by notifying the other active Master-node of the failure.
- Remove the failed VM from a load balancing target by changing the HA Proxy setting.
- OpenStackInfraDriver deletes failed VM.
- OpenStackInfraDriver creates a new VM as a replacement for a failed VM.
- MgmtDriver heals the Kubernetes cluster in
heal_end.- MgmtDriver setup new Master-node on new VMs. This setup procedure can be implemented with the shell script or the python script including installation and configuration tasks.
- Invoke the script for repairing etcd cluster if the Heal target is Master-node.
- Invoke the script for changing HA proxy configuration.
Note
The failed VMs are expected to be identified by checking vnfcInstanceId parameter in the Heal request. In case of this parameter is null, it means that entire rebuild is required. Those procedure is defined in the specification of etsi-nfv-sol-rest-api-for-VNF-deployment6.
Note
To identify the VMs newly created, it is assumed that information such as the number of Worker-node VMs before Heal and the creation time of each VM will need to be referenced.
Following sequence diagram describes the components involved and the flow of Healing Master-node operation:
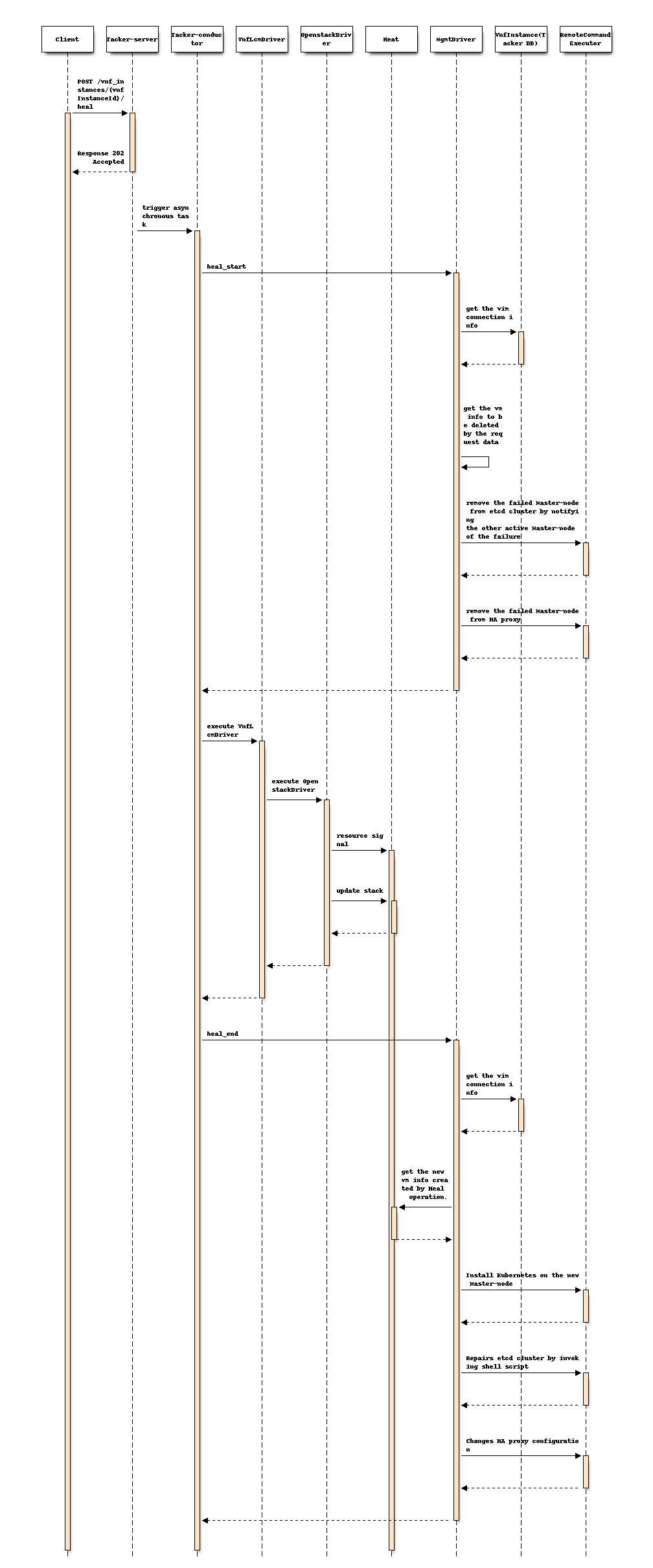
The procedure consists of the following steps as illustrated in above sequence:
- Client sends a POST request to the Heal VNF Instance resource.
- Basically the same sequence as described in the "3) Flow of Heal of a VNF instance "chapter of spec etsi-nfv-sol-rest-api-for-VNF-deployment, except for the MgmtDriver.
- The following processes are performed in
heal_start.- MgmtDriver gets Vim connection information in order to get failed Kubernetes cluster information such as auth_url.
- MgmtDriver gets the failed VM information by checking vnfcInstanceId parameter in the Heal request.
- MgmtDriver remove the failed Master-node from etcd cluster by notifying the other active Master-node of the failure.
- MgmtDriver Remove the failed VM from a load balancing target by changing the HA Proxy setting.
- OpenStack Driver uses Heat to delete failed VM.
- OpenStack Driver uses Heat to create a new VM.
- The following processes are performed in
heal_end.- MgmtDriver gets Vim connection information in order to get existing Kubernetes cluster information such as auth_url.
- MgmtDriver gets the new VM information from the stack resource in Heat.
- MgmtDriver install and configure the Master-node on the VM by invoking a shell script using RemoteCommandExecutor.
- MgmtDriver adds the new Master-node to etcd cluster by invoking shell script using RemoteCommandExecutor.
- MgmtDriver changes HA proxy configuration by invoking shell script using RemoteCommandExecutor.
Healing a Worker-node
The following changes are needed:
- Extend MgmtDriver to support
heal_startandheal_end- In
heal_start- Try evacuating the pod running on the failed VM to another worker node.
- Remove the failed Worker-node by notifying the existing Master-node of the failure.
- In
heal_endthe same as
scale_enddescribed in the specification of mgmt-driver-for-k8s-scale.MgmtDriver setup new Worker-node on new VMs in
heal_end. This setup procedure can be implemented with the shell script or the python script including installation and configuration tasks.
- In
Note
It is assumed that the required information for Heal operation in MgmtDriver is stored in the additional parameter of the Instantiate and/or Heal request. MgmtDriver passes them to the sample script.
The diagram below shows VNF Heal operation for a Worker-node:
+---------------+
| Heal |
| Request with |
| Additional |
| Params |
+---+-----------+
|
+----------------+-----------+
| v VNFM |
| +-------------------+ |
| | Tacker-server | |
| +---------+---------+ |
| | |
4. heal_end | v |
Kubernetes cluster | +----------------------+ |
(Worker) | | +-------------+ | |
+----------------------+--+----| MgmtDriver | | |
| | | +-----------+-+ | |
| | | | | |
| | | 1. heal_start | | |
| | | Kubernetes | | |
+--------------------+----------+ | | cluster | | |
| | | | | (Worker)| | |
| | | | | | | |
| | | | | | | |
| +----------+ +---+------+ | | | | | |
| | | | v | | 3. Create | | +-----------+ | | |
| | +------+ | | +------+ | | new VM | | |OpenStack | | | |
| | |Master| | | |Worker| |<--------------+--+-|InfraDriver| | | |
| | +------+ | | +------+ | | | | +------+----+ | | |
| | VM | | VM | | | | | | | |
| +----------+ +----------+ | | | | | | |
| +----------+ +----------+ | 2. Delete | | | | | |
| | +------+ | | +------+ | | failed VM | | | | | |
| | |Master| | | |Worker| |<--+-----------+--+--------+ | | |
| | +------+ | | +------+ | | | | | | |
| | VM | | VM |<--+-----------+--+----------------+ | |
| +----------+ +----------+ | | | | |
+-------------------------------+ | | Tacker-conductor| |
+-------------------------------+ | +----------------------+ |
| Hardware Resources | | |
+-------------------------------+ +----------------------------+The diagram shows related component of this spec proposal and an overview of the following processing:
MgmtDriver pre-processes to remove Worker-node from the Kubernetes cluster in
heal_startbefore deleting the failed VM.- Try evacuating the pod running on the failed VM to another worker node.
- Remove the failed Worker-node by notifying the existing Master-node of the failure.
OpenStackInfraDriver deletes failed VM.
OpenStackInfraDriver creates a new VM as a replacement for a failed VM.
MgmtDriver heals the Kubernetes cluster in
heal_end.This Heal procedure is basically the same as
scale_enddescribed in the specification of mgmt-driver-for-k8s-scale.MgmtDriver setup new Worker-node on new VMs in
heal_end. This setup procedure can be implemented with the shell script or the python script including installation and configuration tasks.
Note
The failed VMs are expected to be identified by checking vnfcInstanceId parameter in the Heal request. In case of this parameter is null, it means that entire rebuild is required. Those procedure is defined in the specification of etsi-nfv-sol-rest-api-for-VNF-deployment7.
Note
To identify the VMs newly created, it is assumed that information such as the number of Worker-node VMs before Heal and the creation time of each VM will need to be referenced.
Following sequence diagram describes the components involved and the flow of Heal the Worker-node operation:
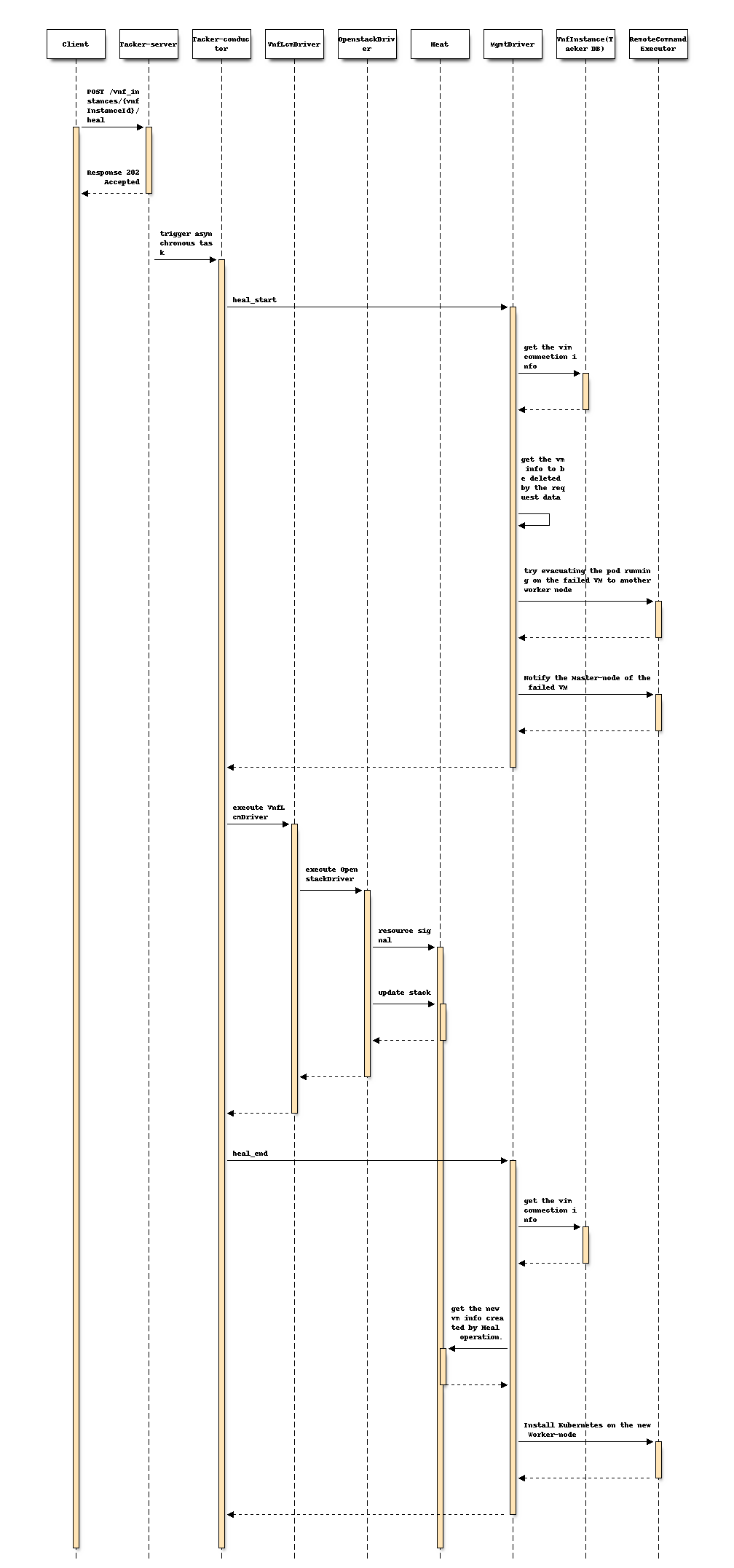
The procedure consists of the following steps as illustrated in above sequence:
- Client sends a POST request to the Heal VNF Instance resource.
- Basically the same sequence as described in the "3) Flow of Heal of a VNF instance "chapter of spec etsi-nfv-sol-rest-api-for-VNF-deployment, except for the MgmtDriver.
- The following processes are performed in
heal_start.- MgmtDriver gets Vim connection information in order to get failed Kubernetes cluster information such as auth_url.
- MgmtDriver gets the failed VM information by checking vnfcInstanceId parameter in the Heal request.
- Try evacuating the pod running on the failed VM to another worker node.
- Remove the failed Worker-node by notifying the existing Master-node of the failure.
- OpenStack Driver uses Heat to delete failed VM.
- OpenStack Driver uses Heat to create a new VM.
- The following processes are performed in
heal_end.- MgmtDriver gets Vim connection information in order to get existing Kubernetes cluster information such as auth_url.
- MgmtDriver gets the new VM information from the stack resource in Heat.
- MgmtDriver setup a Worker-node on the VM by invoking shell script using RemoteCommandExecutor.
Healing a Kubernetes cluster with SOL003
Basically, Heal operation for the entire Kubernetes cluster is based
on the spec of mgmt-driver-for-k8s-cluster,
which specifies operations for instantiation and termination. For
deleting an existing resource in a Heal operation,
heal_start is same as terminate_end, and for
generating a new resource in a Heal operation, heal_end is
same as instantiate_end. During the Heal of the entire VNF
instance, the VIM information must be deleted and the old Kubernetes
cluster information stored in the vim_connection_info of
the VNF Instance table must also be cleared. These operations are
required to be implemented in both heal_start and
terminate_end.
Following sequence diagram describes the components involved and the flow of Heal operation for an entire VNF instance:
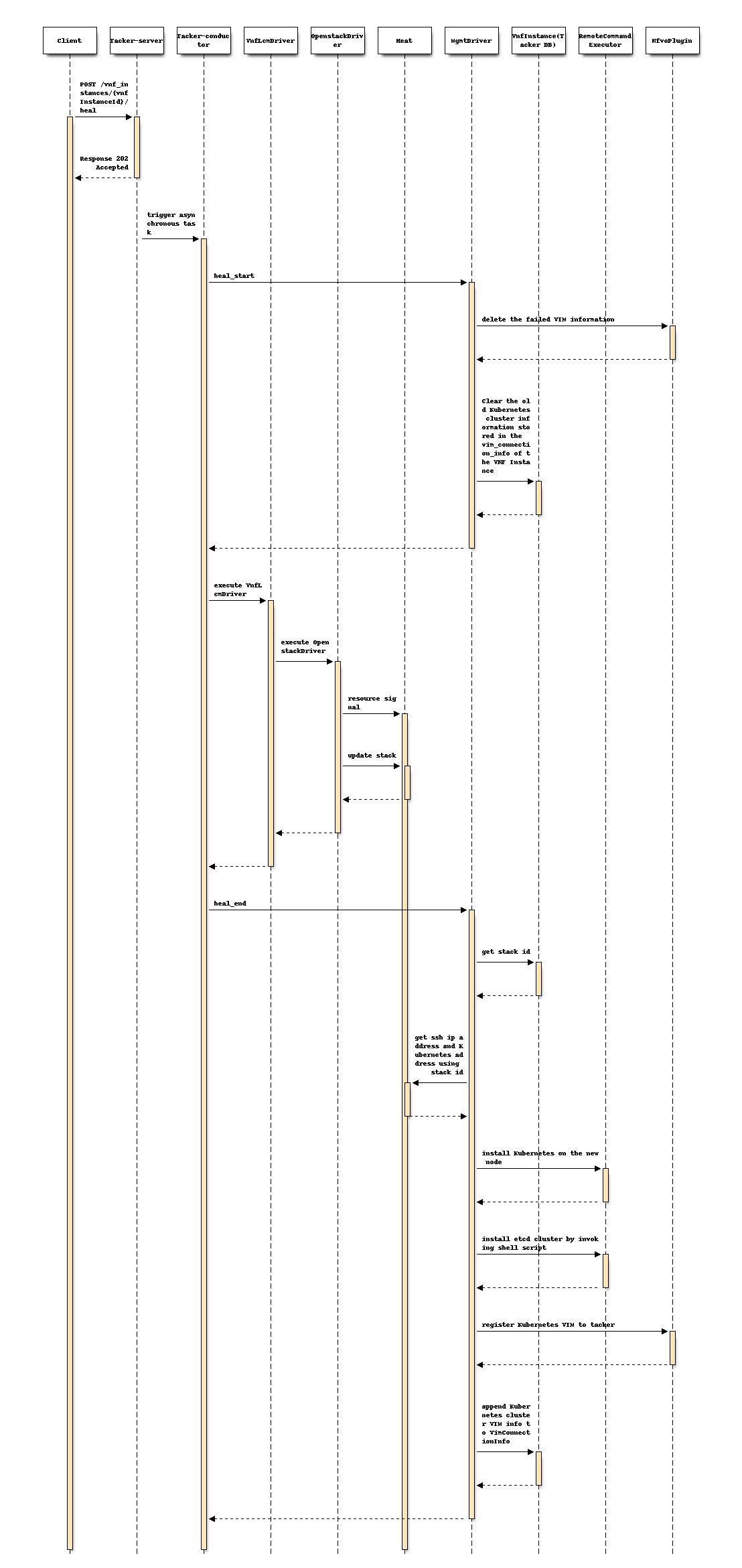
The procedure consists of the following steps as illustrated in above sequence:
- Client sends a POST request to the Heal VNF Instance resource.
- Basically the same sequence as described in the "3) Flow of Heal of a VNF instance "chapter of spec etsi-nfv-sol-rest-api-for-VNF-deployment, except for the MgmtDriver.
heal_startworks the same as mgmt-driver-for-k8s-cluster of terminate_end.- OpenStack Driver uses Heat to delete failed VM.
- OpenStack Driver uses Heat to create a new VM.
heal_endworks the same as mgmt-driver-for-k8s-cluster of instantiate_end.
Alternatives
None
Data model impact
None
REST API impact
None
Security impact
None
Notifications impact
None
Other end user impact
None
Performance Impact
None
Other deployer impact
None
Developer impact
None
Implementation
Assignee(s)
- Primary assignee:
-
Yoshito Ito <yoshito.itou.dr@hco.ntt.co.jp>
- Other contributors:
-
Shotaro Banno <banno.shotaro@fujitsu.com>
Ayumu Ueha <ueha.ayumu@fujitsu.com>
Liang Lu <lu.liang@fujitsu.com>
Work Items
- MgmtDriver will be modified to implement:
- Support the healing of Kubernetes nodes in
heal_startandheal_end. - Provides the following sample script executed by MgmtDriver:
- to incorporate the new Master-node into the existing etcd cluster.
- to change HA Proxy settings due to replacement of old and new VMs in
the process of
heal_startandheal_end
- Support the healing of Kubernetes nodes in
- Add new unit and functional tests.
Dependencies
This spec depends on the following specs:
heal_end referred in "Proposed change" is based on
instantiate_end in the spec of mgmt-driver-for-k8s-cluster.
Healing operation for individual Master-node is performed assuming that
the Kubernetes cluster is an HA configuration, as described in the spec
of mgmt-driver-for-ha-k8s.
Also, Healing operation for individual Worker-node is referring mgmt-driver-for-k8s-scale
for the scale_start.
Testing
Unit and functional tests will be added to cover cases required in the spec.
Documentation Impact
Complete user guide will be added to explain Kubernetes cluster Healing from the perspective of VNF LCM APIs.